从单 Master 到生产级高可用:一次 Kubernetes 架构演进的完整思考¶
本文约 1000 字,阅读约需 5 分钟。
从“能用”到“可靠”,往往只差一次架构升级。这篇文章记录了我将实验环境从单控制平面,演进为生产级高可用架构的全过程思考与取舍。
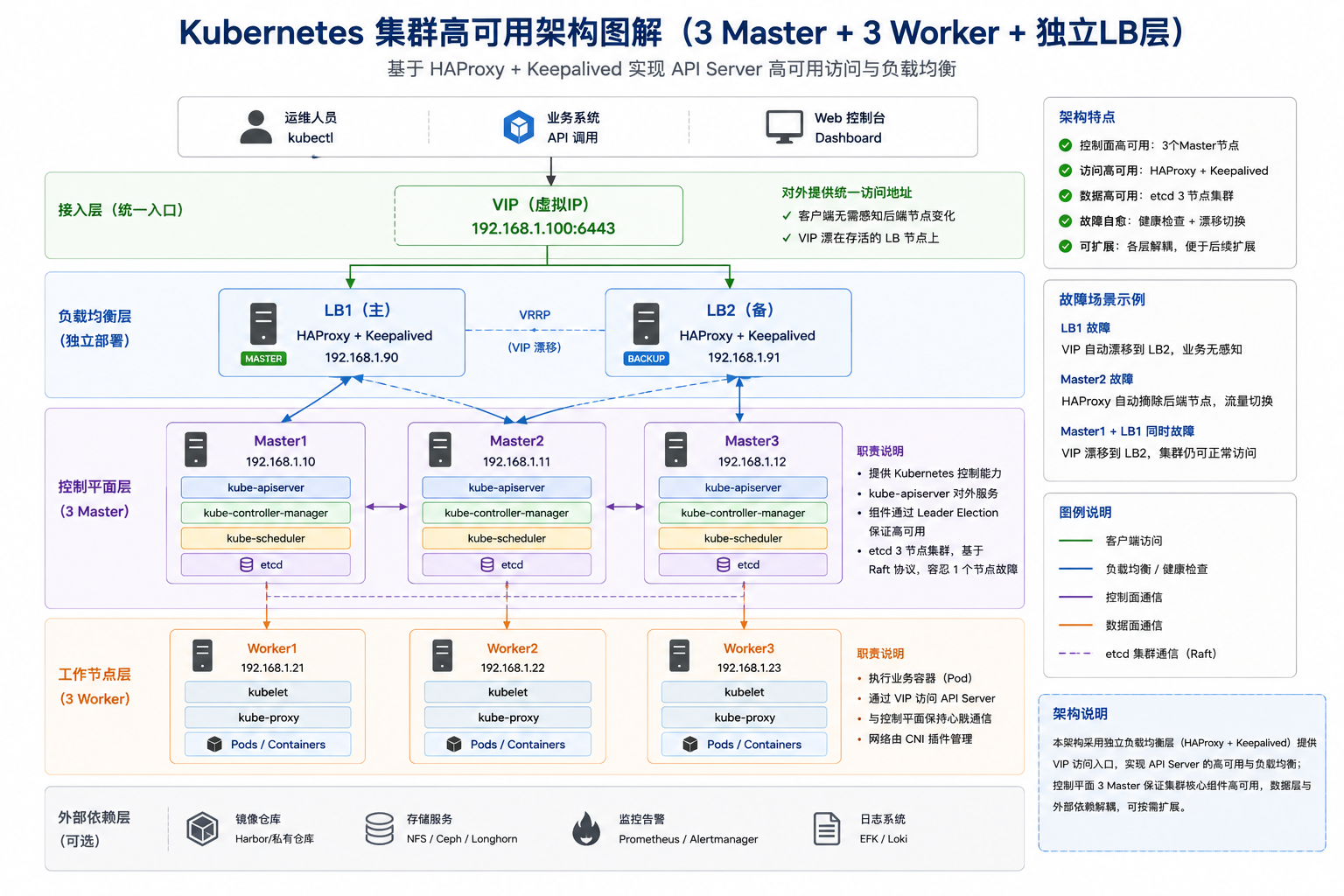
一、背景:一个实验集群的“边界”¶
在「从 0 到企业级私有云」系列中,最初搭建的是一套典型入门结构:
1 Master + 3 Worker
这套架构的初衷很明确:
- 快速验证 Kubernetes 核心能力
- 跑通 CI/CD 与基础服务
- 构建最小可用集群
在早期阶段,这样的设计完全合理,甚至是最优解。
但随着使用逐渐深入,当开始承载一些长期运行的基础组件(监控、日志、CI系统) ,并尝试模拟真实故障时,这套架构的“边界”开始显现:
- Master 一旦重启,控制面立即不可用
- 调度、扩缩容、发布流程全部中断
- 无法进行任何“不中断服务”的运维操作
本质问题只有一个:
控制面存在单点故障(SPOF)
这意味着,这套架构始终停留在:
👉 “可用”,但不“可靠”
二、架构升级目标¶
这次重构,并不是简单“加机器”,而是一次明确目标的架构演进:
对应的方案是:
3 Master + 3 Worker + HAProxy + Keepalived
三、新架构:从单点到多活¶
3.1 核心拓扑¶
在资源受限的场景下,HAProxy 与 Keepalived 也可以直接部署在 Master 节点上,这是一种在中小规模私有云中较为常见的折中方案。不过,从架构演进的角度来看,将接入层独立出来,往往是走向生产级设计的重要一步。
四、关键设计思路(核心价值)¶
这一部分,是整个架构最有价值的地方。
4.1 为什么是 3 Master?¶
不是经验结论,而是分布式系统的基本原则:
多数派(Quorum)机制
etcd 基于 Raft 协议:
- 2 节点 → 无法容错
- 3 节点 → 可容忍 1 个故障
- 5 节点 → 可容忍 2 个故障(但成本更高)
因此:
3 是生产级控制面的最小规模
4.2 为什么需要 HAProxy?¶
Kubernetes 控制面的核心入口是:
kube-apiserver
当存在多个 Master 时,必须解决一个问题:
👉 客户端访问哪个 API Server?
HAProxy 的引入,本质上解决了两件事:
同时通过健康检查:
👉 自动摘除异常节点
4.3 为什么还需要 Keepalived?¶
很多架构在这里容易出现一个误区:
👉 认为有 HAProxy 就已经高可用了
但实际上:
HAProxy 自身也可能成为单点
Keepalived 的作用是:
最终效果:
入口地址永远不变,但后端节点可动态切换
4.4 高可用是如何实现的?¶
这套架构的高可用,并不是依赖某一个组件,而是多层叠加:
- API Server:多实例 + LB
- HAProxy:多实例 + VIP 漂移
- etcd:多数派机制
- 控制组件:Leader Election
本质上实现的是:
“无单点”设计(No Single Point of Failure)
4.5 从混合部署到独立 LB 层¶
在早期或资源受限的环境中,HAProxy 与 Keepalived 通常会与 Master 节点进行混合部署,这种方式能够在较低成本下实现控制面的高可用能力,是中小规模私有云中较为常见的一种折中方案。
但随着集群逐步承载实际业务,这种部署方式也会逐渐暴露出一些局限:
- 控制面与流量入口耦合,单节点故障影响范围扩大
- HAProxy 与 etcd、kube-apiserver 之间存在资源竞争(CPU / IO)
- 架构扩展能力受限(难以独立扩展或替换负载均衡层)
因此,在本次架构升级中,对接入层进行了进一步拆分,将 HAProxy 与 Keepalived 从 Master 节点中剥离,独立部署为专用的负载均衡层:
LB1:HAProxy + Keepalived
LB2:HAProxy + Keepalived
Master1:kube-apiserver
Master2:kube-apiserver
Master3:kube-apiserver
这一调整的核心价值,并不只是“多了两台机器”,而在于实现了更清晰的架构分层:
- 接入层(LB) :负责流量入口与高可用切换
- 控制面(Master) :负责集群调度与状态管理
从架构设计角度来看,这种拆分带来了几个关键收益:
1️⃣ 故障域隔离¶
负载均衡层与控制面解耦后,单一节点故障不会同时影响多个关键角色,从而降低系统整体风险。
2️⃣ 资源隔离¶
HAProxy 属于高并发网络组件,而 etcd 与控制面组件对 IO 和稳定性较为敏感。独立部署后,可以避免资源争用带来的性能抖动。
3️⃣ 架构可扩展性提升¶
独立的 LB 层可以根据需要进行横向扩展,或在后续演进中替换为其他实现(如云负载均衡或 MetalLB),而无需影响控制面结构。
需要注意的是,这种架构在带来更高可靠性的同时,也引入了额外的节点成本与运维复杂度。因此,在实际落地时,仍需根据集群规模与业务需求进行权衡。
从演进路径来看,可以将两种模式理解为:
这也是从“可用架构”迈向“生产级架构”的一个重要阶段。
五、新旧架构对比(最直观的变化)¶
| 维度 | 单 Master 架构 | 高可用架构 |
|---|---|---|
| 控制面可用性 | ❌ 单点 | ✅ 多节点容错 |
| 运维能力 | ❌ 无法滚动升级 | ✅ 支持逐节点维护 |
| API 访问 | ❌ 固定 IP | ✅ VIP + 负载均衡 |
| etcd 安全性 | ❌ 单副本 | ✅ 多副本 |
| 架构复杂度 | 低 | 中 |
| 生产适用性 | ❌ | ✅ |
这次升级,本质是完成了一次:
从“实验架构”到“生产架构”的跃迁
六、适用场景分析¶
这套架构并不是“通用最优解”,它有明确边界。
✅ 适用场景¶
- 中小规模私有云(\< 100 节点)
- 无云厂商 LB 的环境(裸金属 / 内网)
- 对稳定性有要求的内部平台
- 技术能力建设与架构实践
❌ 不适合场景¶
- 超大规模集群(需独立 etcd 或托管控制面)
- 资源极度受限环境
- 单机学习环境
七、隐藏成本与注意事项¶
架构升级带来的不仅是收益,还有成本:
7.1 etcd 仍然是关键瓶颈¶
默认情况下:
etcd 与 Master 共节点
这意味着:
- IO 性能直接影响集群稳定性
- 磁盘与网络要求提高
7.2 架构复杂度上升¶
引入组件:
- HAProxy
- Keepalived
- 多 Master
意味着:
7.3 不是终点,而是阶段¶
当前架构仍然只是“第一阶段生产级”:
未来可以继续演进:
- 独立 etcd 集群
- 多集群架构
- 云原生负载均衡(MetalLB / 云LB)
- GitOps 管理
八、总结¶
这次从 1 Master 到 3 Master 的升级,本质并不是规模扩展,而是理念转变:
从“把服务跑起来” → 到“让系统稳定运行”
也是从“使用 Kubernetes”到“设计 Kubernetes 架构”的第一步。